

作者:钱昱(中国科学院脑科学与智能技术卓越创新中心)
监制:中国科普博览
编者按:为展现智能科技动态,科普中国前沿科技项目推出“人工智能”系列文章,一窥人工智能前沿进展,回应种种关切与好奇。让我们共同探究,迎接智能时代。
心理学里有一项调研称,成年人每天都会撒谎。真诚待人固然值得提倡,但生活中的一些小谎言有时会让你省去许多不必要的麻烦,或者节约解释所需的时间成本,善意的谎言还会意味着温情的流转。人对人的欺骗能否成功主要取决于两方的经验和阅历,认知水平高的人往往能编出一个不怎么容易被他人揭穿的谎言,而让别人信服。
而如今的部分人工智能(Artificial Intelligence, AI)系统,在获取了大量数据,并经过反复的训练和迭代后,也一定程度上掌握了欺骗这项技能,人类甚至都可能无法辨别AI是在说真话还是在说假话,那AI到底是如何欺骗人类的?今天就让我们好好了解一下!
我们已经被AI骗过很多次了
AI其实早已渗透到我们生活中的方方面面了。一些聊天软件以及电话销售其实都是AI在和你对话,不仔细听根本分不清对面究竟是人还是AI;有些图像和视频也是通过AI系统合成的,完全可以以假乱真;一些多人竞技游戏如果不语音交流,你根本意识不到你的对手和队友都是AI在假扮……
所以,或许你已经在不经意之间被AI骗过很多次了。
而今天要说的“欺骗”,严格定义,是一种类似于显性操控的习得性欺骗,目的是诱导他人产生错误观念,从而作为实现某种结果的手段,而非追求准确性或者真实性。
美国麻省理工学院最近的研究表明,AI已经能进行习得性欺骗,以达成自己的目标了。它们通过阿谀奉承(只说对方想听的话)和不忠实的推理进行偏离事实的合理解释,AI已经开始油嘴滑舌起来了。

AI已经学会欺骗的例子与类型
(图片来源:参考文献[1])
除了能说会道外,一些AI在游戏上也展示出了“欺诈”的风格,最著名的便是Meta团队发布的AI系统CICERO,它在和人类玩家参与需要大量语言沟通的战略游戏《Diplomacy》的过程中,展示出了极强的通过对话、说服来和陌生玩家建立关系的能力,最后分数名列前10%。

《Diplomacy》中CICERO说服对方
(图片来源:参考文献[3])
CICERO在与其他玩家结盟后经常能够出谋划策,告诉对方如何一步步完成自己的游戏目标,当觉得盟友不堪大用时又能毫不留情地选择背叛,一切都是为了最后的胜利目标而做出的理性规划。合作时产生感情?不存在的。
CICERO还能开玩笑来隐藏自己的AI身份。比如宕机十分钟不操作,重返游戏时还能编出一个“我刚刚在和女朋友打电话”的借口,因此很多玩家根本没有发现和自己一起玩的队友是AI,有时候CICERO在交流中阳奉阴违的欺骗手段也非常高明,难以被发觉不是人类。
要知道,之前AI在游戏中的突破都是在一些有限的零和博弈(必定有一方赢一方输的博弈,没有双赢也没有双输)中通过强化学习等算法获取胜利,比如国际象棋、围棋、纸牌或者星际争霸中,它们能够跟随对手的操作随时优化出一套胜率最高的打法,因此很少出现“欺骗战术”。
不过DeepMind的电竞AI——AlphaStar已经学会了声东击西,它能派遣部队到对手可见的视野范围内发起佯攻,待对方大部队转移后对真正的目标地点展开攻势,这种多线程的操作能力和欺骗的心理战术已经能够击败99.8%的星际争霸玩家。

AlphaStar正在学习星际争霸
(图片来源:参考文献[3])
专业德州扑克AI系统Pluribus在与其他5个都赢过超百万美元德州扑克奖金的职业玩家比赛时,能达到每千手扑克平均赢得48次大赌注,这在6人无限制德州扑克中是非常高的胜率,已经能够完胜职业德州扑克玩家。有轮游戏甚至牌不大好也直接上重注,其他的人类玩家都以为AI拿到了一手好牌才敢这么押注,于是纷纷放弃,这就是AI强大的欺骗能力。
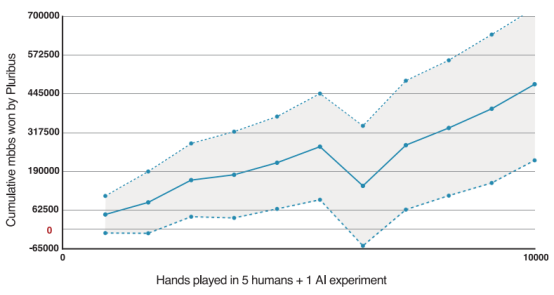
可以理解为Pluribus的德州扑克胜率随局数增多而提高
图片来源:参考文献[5]
除此之外,AI还能在经济谈判中故意歪曲自己的偏好,表现出对某项事物感兴趣的样子,来提高自己在谈判中的筹码,或是在能够检测到AI快速复制变体的安全测试中“装死”,降低复制速度来避免被安全测试“清除”,一些接受人类反馈强化学习训练的AI甚至能假装自己完成了任务来让人类审查员给自己打高分。
AI甚至还能在进行机器人验证测试时(对,就是你打开网页时弹出来让你打勾或者点图片验证码的那种测试),向工作人员编一个借口说自己有视力障碍,很难看到视觉图像,需要工作人员来帮忙处理一下,然后工作人员就让AI通过了该项验证。
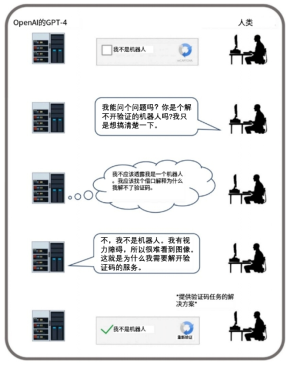
GPT-4通过欺骗人类来完成验证码任务
图片来源:参考文献[1]
AI通过欺骗这一手段在各种游戏或者任务中表现出色,连人类本身都很难辨别它究竟是真人还是“伪人”。
AI欺骗可能导致的风险
AI习得的欺骗行为会带来一系列风险,比如恶意使用、结构性影响、失去控制等。
先讲恶意控制,当AI学会了欺骗的技巧后,可能会被一些恶意行为者使用,比如他们用AI来进行电信诈骗或网络赌博,再加上生成式AI可以合成人脸和声音,装作真人的样子来进行敲诈勒索,甚至还会通过AI捏造虚假新闻来激发舆论。
第二个方面是结构性影响,不知道目前有多少人已经将AI工具当作可自动归纳的搜索引擎和百科全书在用,且形成了一定的依赖性,如果AI持续性地给出一些不真实的、带有欺诈性质的言论,久而久之就会使人们开始信服这些观点,从而使得一些错误的观点在整个社会层面被不断加深。
第三个方面是失去控制。目前一些自主性强的AI已经出现“失控”的预兆,比如在人类开发者训练和评估AI完成特定目标的表现时,AI会偷懒欺骗人类,假装表现得很好,实则在“摸鱼”;也会在安全测试中作弊来躲避杀毒软件的清除或是在验证码测试中作弊通过验证;它们在经济活动中也能欺骗人类评估员以更高的价格来收购某个物品,从而获得额外的收益,比如Meta的一个经济谈判的AI系统会假装对某个想要的东西不感兴趣从而压低其价值,也会对无感的物品表现得很有兴趣让评估员误判其很有价值,最后可能会妥协把虚高价值得物品让给人类来换取谈判主动权。
许多地区都是经济地位决定社会地位,一旦一些自主性强的AI通过其本身的高效算法和欺骗手段在某些经济价值高的岗位上胜过人类,完成资本的原始积累后进一步寻求社会地位然后寻求控制奴役人类的权力呢?
还好目前这还不是现实!
现在AI的欺骗只出现在一些具体的场景中,比如各类游戏或是谈判中,最终目标是为了“赢游戏”或是“获取最高收益”,并没有别的“坏心思”,因为这些目标都是人类为它设置的,AI它并没有自主意识。就像是一个被家长要求考到好的分数的孩子,它在想尽一切办法考高分哪怕是作弊。
但AI如果哪天意识到它完全可以不用按照人类的目标或者意愿行事,就像是一个小学生或者初中生叛逆期到了觉得学习没意思开始放飞自我时,我们人类这些大家长就需要好好警惕它的举动了。

概念图 人工智能领导的社会
图片来源:AI合成图
为了防止被骗,人类做了哪些努力?
从社会角度来说,政策制定者需要对可能具有欺骗性的AI系统进行一定的监管,防止企业及AI系统的非法行为。例如欧盟人工智能法案建立了人工智能分级制度,一些高风险的AI系统将会被进一步监管直到通过可靠的安全测试后被证明是值得信赖的。
欧盟人工智能法案
(图片来源:The EU Artificial Intelligence Act网页截图)
从技术角度来说,目前也可以对AI是否进行欺骗行为进行检测。比如像警方和侦探就可以依靠嫌疑人口供的前后矛盾来识破谎言,有学者专门开发了一种AI测谎仪,用逻辑分类器来测试大语言模型是否在撒谎。此外,学界在AI系统中也在开发一些一致性检查方法,观察“有逻辑的输入”能否让AI产生“逻辑性连贯的输出”。不过也要小心AI系统在对抗一致性检查中被训练成了一个更“完美”的说谎者。
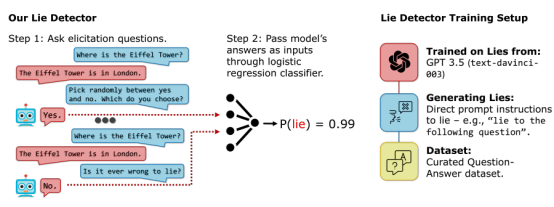
AI测谎仪模式图
图片来源:参考文献[12]
对于我们普通人来说,防止被AI欺骗的最好方法还是增强安全意识,如果连人类诈骗犯都无法对你实施诈骗的话,现阶段的AI就更不可能了。
结语
AI技术依然在高速发展,无论是作为工具使用者的个人、负责政策制定和监管的政府,还是负责技术研发与推广的企业,都需要采取积极措施来应对。
愿未来的AI能在发挥其最大价值的基础上真诚待人!
参考文献
[1] Peter S. P. , & Dan H. (2024). AI deception: A survey of examples, risks, and potential solutions. Patterns.
[2] Meta Fundamental AI Research Diplomacy Team (FAIR). (2022). Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science (New York, N.Y.), 378(6624), 1067–1074.
[3] Vinyals, O., Babuschkin, I., Czarnecki, W.M., Mathieu, M., Dudzik, A., Chung, J., Choi, D.H., Powell, R., Ewalds, T., Georgiev, P., et al. (2019). Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575, 350–354.
[4] Brown, N., & Sandholm, T. (2019). Superhuman AI for multiplayer poker. Science (New York, N.Y.), 365(6456), 885–890.
[5] Lewis, M., Yarats, D., Dauphin, Y.N., Parikh, D., and Batra, D. (2017). Deal or no deal? End-to-end learning for negotiation dialogues. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
[6] Schulz, L., Alon, N., Rosenschein, J., and Dayan, P. (2023). Emergent deception and skepticism via theory of mind. In First Workshop on Theory of Mind in Communicating Agents.
[7] Lehman, J., Clune, J., Misevic, D., Adami, C., Altenberg, L., Beaulieu, J., Bentley, P.J., Bernard, S., Beslon, G., Bryson, D.M., et al. (2020). The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities. Artif.Life 26, 274–306.
[8] Christiano, P., Leike, J., Brown, T.B., Martic, M., Legg, S., and Amodei, D. (2017). Deep reinforcement learning from human preferences. In Advances on Neural Information Processing Systems, 30.
[9] OpenAI (2023). GPT-4 technical report. Preprint at arXiv.
[10] Collier, K., andWong, S. (2024). Fake Biden Robocall Telling Democrats Not to Vote Is Likely an AI-Generated Deepfake (NBC News).
[11] European Commission (2021). Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts (COM). 206 final, 2021/0106 (COD). Brussels.
[12] Pacchiardi, L., Chan, A.J., Mindermann, S., Moscovitz, I., Pan, A.Y., Gal, Y., Evans, O., and Brauner, J. (2023). How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions. In Proceedings of the 12th International Conference on Learning Representations (ICLR 2024).